XPath is an XML path used to navigate through elements and attributes in an XML document or HTML DOM structure of a web page. XPath is used in Selenium Webdriver, LeanFT, and UFT to locate any element on a web page using XML path expression. Please refer following links to know the uses of XPath in UFT and LeanFT.
How To Use XPath in LeanFT
Uses of XPath in UFT To Identify Web-Based Objects
XPath provides numerous ways to find web elements on a web page. Using XPath in Selenium Webdriver we can easily identify those elements which sometimes become very difficult or next to impossible to identify by using other approaches. For example, locating dynamic elements has always been a challenging task and a painful area in automating modern complex web applications.
In this article, you will see various ways of identifying web elements via XPath in Selenium Webdriver with examples. Having said that, the concept explained here is generic and can be applied to other automation tools like UFT and LeanFT as well.
Types Of XPath
There are two types of XPath
- Absolute XPath
- Relative XPath
Absolute XPath
In absolute XPATH, the XPath expression is created from the Root Element with the single forward-slash(/) to the desired element. Absolute XPath is very fast as compared to relative XPath because it contains the complete path. However, it not recommended using because if in future the position of the element changes in the page the test would start getting fail.
Example: The following XPath is the path of a submit button on a page.
|
1 2 3 |
/html/body/div[1]/div[1]/div/div[2]/div/div/form/span/section/div/div[3]/button |
In the above XPath, if a new div tag is added or removed, the XPath would become invalid to identify the desired element.
Relative Xpath
The relative Xpath starts from the middle of the HTML DOM structure. It always starts with a double forward-slash (//) indicating the current node. It is used to search elements anywhere on the webpage based on the provided element TagName and properties(attribute and its value). The relative XPath is quite short, readable, and easy to use. Since it directly points to the desired element on the page so there is very little probability to fail the test if later on the location of the element is changed on the page. The syntax for creating relative XPath is as follows.
|
1 2 3 |
Xpath=//tagname[@attribute='attribute value'] |
Let’s see how to write relative XPath for the ‘Email or Phone‘ element of the Gmail login page. The following is the DOM structure of the ‘Email or Phone‘ element.

|
1 2 3 |
<input type="email" class="whsOnd zHQkBf" jsname="YPqjbf" autocomplete="username" spellcheck="false" tabindex="0" aria-label="Email or phone" name="identifier" value="" autocapitalize="none" id="identifierId" dir="ltr" data-initial-dir="ltr" data-initial-value=""> |
The TagName of the ‘Email or Phone‘ element is input and it has multiple attributes and one of them is its id. Usually, the ID of every element is unique on a page. The id of this field is identifierId.
The following basic XPath expression can be used to locate the ‘Email or Phone‘ element anywhere on the page based on its ID.
|
1 2 3 |
Xpath=//input[@id='identifierId'] |
XPath to Handle Dynamic & Complex Elements
Basic XPath
XPath expression is used to locate an element or elements using the combination of TagName and attributes like ID, Name, Class, Img, etc. The following are a few basic XPath examples.
- Xpath=//input [@name=’username’]
- Xpath=//input[@id=’id_txt1’]
- Xpath=//*[@id=”aw0″]
- Xpath=//img[@src= ‘https://abcd.com/simgad/test.png’]
-
Xpath=//a[@href=’http://abcd.com/’]
Using AND & OR Operator in XPath
As the name implies these logical operators are used to combine more than one the attribute using AND or OR condition. In the case of OR operator, at least one condition should be true or both, whereas, in the case of AND operator, all given conditions should be true. The following is the DOM structure for the username field.
|
1 2 3 |
<input aria-label="userid" name="username" type="text" id="txt_1" class="xih-highlight""> |
XPath using AND Operator. Both the provided attribute value should be matched.
|
1 2 3 |
XPath=//input[@name='username' and @id='txt_1'] |
Note: You can add more attributes and their values using AND operator unless the element is identified uniquely on the webpage.
XPath using OR Operator
|
1 2 3 |
XPath=//input[@name='username' or @id='txt_1'] |
The above XPath will work if the element can be identified uniquely using any of the attributes and its value.
Note: If required you can add more attributes and their values using OR operator.
By Joining Multiple XPath
Multiple XPath expressions can be joined to identify the required element on the page. This can be used in places where there is a parent element under which there are multiple child elements.
Let’s see the following DOM Structure.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
<form action="/login" method="post" class=""> <div class="form-group"> <label><strong>User Name</strong></label> <input type="text" class="form-control xh-highlight" name="username" id="username" placeholder="Enter User Name" value=""> </div> <div class="form-group"> <label><strong>Password</strong></label> <input type="password" class="form-control" name="password" id="password" placeholder="Enter Password"> </div> <div class="checkbox"> <label> <input type="checkbox" name="remember-me" id="remember-me" class=""> Remember Me </label> </div> <button type="submit" id="submit" class="btn btn-success btn-flat m-b-30 m-t-30">Sign in</button> <div class="register-link m-t-15 text-center"> <p>Don't have account ? <a href="/signup"> Sign Up Here</a></p> </div> </form> |
As per the DOM Structure, a parent element is a form and under which there are multiple child elements like the username text box.
We can use the following XPath to locate the parent form element.
|
1 2 3 |
XPath=//form[@action='/login'] |
To locate the username text box the XPath would be as follows.
|
1 2 3 |
XPath=//input[@name='username'] |
The above two XPath can be joined together in the following way to locate the username text box.
|
1 2 3 |
XPath = //form[@action='/login']//input[@name='username'] |
XPath Functions
Text() Method
The XPath text() method is used to locate elements based on the text of a web element. It finds the element on the web page by matching the exact text that is provided in the XPath.
The HTML Tag for the ‘User Name‘ label in the following image is as follows.
|
1 2 3 |
<strong class="">User Name</strong> |

To locate the ‘User Name‘ label the using text() method XPath will be as follows.
|
1 2 3 |
XPath=//strong[text()='User Name'] |
Contains() Method
The contains method is very useful in identifying elements when values of some of the attributes change dynamically. If some part of the attribute values (either prefix or suffix) of the element are fixed and the rest of the part is dynamic in nature the contains() method becomes very handy. It can identify an element or elements by providing the partial value of the attribute value.
|
1 2 3 |
<input type="text" class="form-control" name="username" id="username" placeholder="Enter User Name" value=""> |
In the above HTML tag, the attribute placeholder has the value ‘Enter User Name‘.The following XPath expressions can be used to identify the username element.
|
1 2 3 |
XPath=//input[contains(@placeholder,'Enter User')] |
OR
|
1 2 3 |
XPath=//input[contains(@placeholder,'User Name')] |
We can also use the text() method inside the contains() method to identify the element using partial text if there is no attribute in the HTML tag of the element. For example in the following HTML tag class attribute has no value and the strong tag has just a text ‘User Name‘
|
1 2 3 |
<strong class>User Name</strong> |
We can write the following XPath expression to identify the ‘User Name‘ by just passing partial text ‘User‘.
|
1 2 3 |
XPath=//strong[contains(text(),'User')] |
Note: It is not necessary to only pass partial attribute values in the contains() method. It will also work fine if you pass the full attribute value.
Starts-With() Method
The starts-with() method is quite similar to contains() method.However, the only difference is that in starts-with() method we have to pass some initial characters of the attribute values to identify the element with dynamic attribute values. This method is quite helpful when the few initial characters of an attribute are fixed and the remaining of the characters are dynamic. Suppose the id attribute of the particular element is dynamic and it is generated like user_123,user_654,user_307, and so on. So here the fixed characters of the id attribute are “user_“.
|
1 2 3 |
<input type="text" class="hx_bgd" name="user_365" > |
The following XPath expression can be used to locate the required element.
|
1 2 3 |
Xpath=//input[starts-with(@name,'user_')] |
Using Index
This approach is quite useful when you want to find a particular element based on its index value rather than any attribute value. It is also very helpful in locating elements with dynamic attribute values as we are using index value instead of any specific attribute value.

In the above DOM structure, there are three input nodes. To locate any specific node first we will have to write a generic XPath expression that selects all input nodes under the particular form.
- Generic XPath=//form[@action=’/login’]//input
Next, we will have to specify the index of the desired input node with square brackets. The syntax for the complete XPath is as follows.
- XPath=(Generic XPath)[Index] where Index starts with 1
The actual XPath expression to select the second input node will be as follow.
|
1 2 3 |
Xpath=(//form[@action='/login']//input)[2] |
OR
|
1 2 3 |
Xpath=(//form[@action='/login']//input)[position()=2] |
XPath Axes
XPath axes are used to locate/identify parent, child, or sibling web elements(that does not have any unique attribute value) with the reference of a tag that can be easily identified. I have explained a few of the commonly used XPath axes in the following sections.
I will be using the ChroPath extension to explain XPath Axes. You can also install the same in your chrome browser. It is available for Chrome, Edge, Firefox and etc. The benefit of using ChroPath is that once it is installed it becomes available inside the developer’s tool of the browser and highlights the web element/elements for the matched XPath expression.
Following
The following axes return all elements that come after the current tag.
The syntax of Following XPath axes is as follows.
|
1 2 3 |
Xpath=//tagname[attribute='value']/following::tagname |
Let’s try to understand it with the help of the Instagram login page. Open Instagram and inspect the Instagram text.
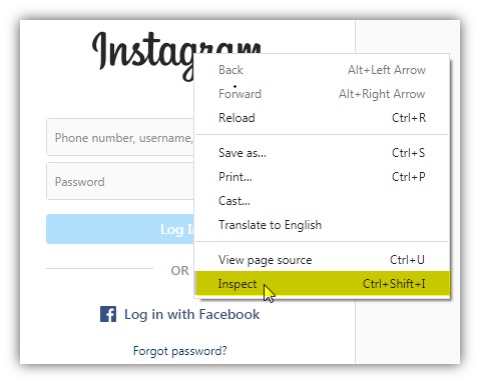 Click on the ChroPath tab in the Developers tool and write the relative XPath for the current node i.e Instagram text.
Click on the ChroPath tab in the Developers tool and write the relative XPath for the current node i.e Instagram text.
|
1 2 3 |
Xpath=//h1[contains(@class,'coreSpriteLoggedOutWordmark')] |
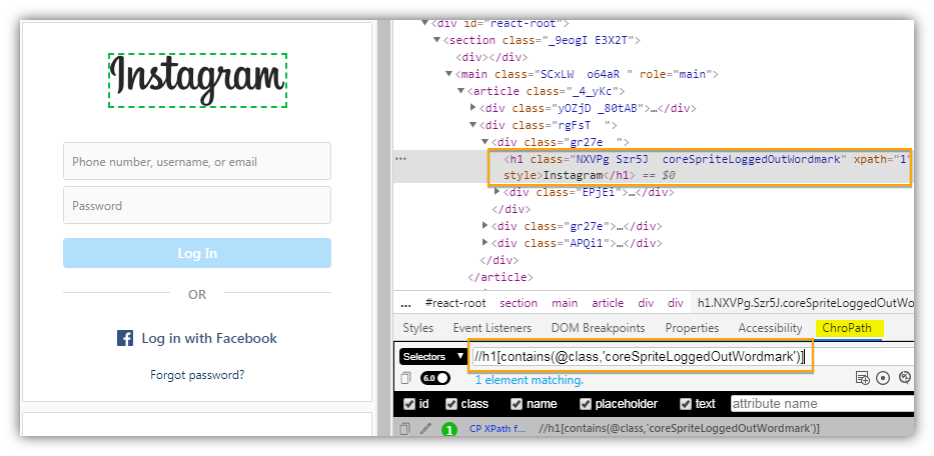 Now we can write XPath expression using the Following axes to locate both username and password text fields. The following XPath expression will locate both input fields.
Now we can write XPath expression using the Following axes to locate both username and password text fields. The following XPath expression will locate both input fields.
|
1 2 3 |
Xpath=//h1[contains(@class,'coreSpriteLoggedOutWordmark')]//following::input |
 You can locate a specific input by providing the index of the input field. The following XPath expression will locate the password field which is at Index 2. An index 1 will locate the username field.
You can locate a specific input by providing the index of the input field. The following XPath expression will locate the password field which is at Index 2. An index 1 will locate the username field.
|
1 2 3 |
Xpath=//*[contains(@class,'coreSpriteLoggedOutWordmark')]//following::input[2] |

Following-Sibling

The following-sibling axes select all sibling nodes after the current node which are at the same level. The syntax for the following-sibling is as follows.
|
1 2 3 |
XPath=//CurrentTag[@attribute ='value']/following-sibling::SiblingTag[@attribute ='value'] |
OR
|
1 2 3 |
XPath=//CurrentTag[@attribute ='value']/following-sibling::SiblingTag[Index] |
For example, the three dropdowns to select the Date, Month and Year are siblings on the Facebook home page as shown in the below screenshot. All three elements are inside the same span tag.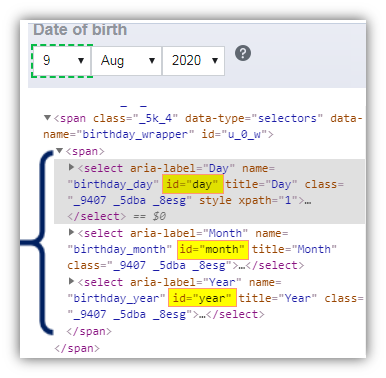 The following XPath expression can be used to locate the current node i.e. Date element.
The following XPath expression can be used to locate the current node i.e. Date element.
|
1 2 3 |
XPath=//select[@title='Day'] |
 Now using the following-sibling axes, we can easily find out the XPath value for the Month and Year dropdowns. I am locating the Month dropdown using the following XPath.
Now using the following-sibling axes, we can easily find out the XPath value for the Month and Year dropdowns. I am locating the Month dropdown using the following XPath.
|
1 2 3 |
XPath=//select[@title='Day']//following-sibling::select[1] |

Preceding
The preceding axes are used to traverse all nodes that come before the current node. It could be the parent or the grandparent node. The following are the syntax for traversing previous tags using preceding axes.
|
1 2 3 |
XPath=//currentTag[@attribute ='value']//preceding-sibling::PreviousTag[@attribute ='value'] |
OR
|
1 2 3 |
XPath=//currentTag[@attribute ='value']//preceding-sibling::PreviousTag |
OR
|
1 2 3 |
XPath=//currentTag[@attribute ='value']//preceding-sibling::PreviousTag[Index] |
Let’s take an example of the Instagram login page and consider the “Forgot Password?” link as the current node.

The XPath expression for the “Forgot Password?” link could be written as follows.
|
1 2 3 |
XPath=//a[@href='/accounts/password/reset/'] |
Now we can select all nodes or any specif by using the preceding axis in the document that comes before the current node.
The ‘Log In‘ button can be selected by the following XPath.
|
1 2 3 |
Xpath=//a[@href='/accounts/password/reset/']//preceding::button[2] |
Likewise, we can locate the username and password input field by the following XPath expressions.
XPath for a password input field is as follows as it comes at index 1 with reference to the “Forgot Password?” link.
|
1 2 3 |
XPath=//a[@href='/accounts/password/reset/']//preceding::input[1] |
XPath for a username input field is as follows as it comes at index 2 with reference to the “Forgot Password?” link.
|
1 2 3 |
XPath=//a[@href='/accounts/password/reset/']//preceding::input[2] |
Preceding-Sibling
The preceding-sibling axes select all sibling nodes before the current node.
The syntax for the preceding-sibling is as follows.
|
1 2 3 |
XPath=//CurrentTag[@attribute ='value']/preceding-sibling::SiblingTag[@attribute ='value'] |
OR
|
1 2 3 |
XPath=//CurrentTag[@attribute ='value']/preceding-sibling::SiblingTag[Index] |
Let’s try to understand this with the same Date, Month, and year dropdown boxes on the Facebook login page.

In the case of the following-sibling, we had selected the Date element as the current node and selected the Month and Year element using the following-sibling axes. Here we will select the Year element as the current node and locate Month and the Date element using preceding-sibling.
The following XPath expression can be used to locate the current node i.e. web element to select the Year for the DOB.
|
1 2 3 |
XPath=//select[@id='year'] |
Now using the preceding-sibling axes, we can easily find out the XPath value for the Month and Year dropdowns. I am locating the Month dropdown using the following XPath.
|
1 2 3 |
XPath=//select[@id='year']//preceding-sibling::select[1] |
The Date element can be located using the following XPath.
|
1 2 3 |
XPath=//select[@id='year']//preceding-sibling::select[2] |
Parent
The parent XPath axes are used to locate the parent tags of the current element tag. The syntax of locating parent axes is as follows.
|
1 2 3 |
XPath=//CurrentTag[@attribute ='value']/parent::tagName |
The grandparent can be located as follows.
|
1 2 3 |
XPath=//CurrentTag[@attribute ='value']/parent::tagName/parent::tagName |
Let’s understand it using the google search page. We will consider the Google Search button as the current element and using this current element and parent axes, we will locate the Google Search text box.
The following XPath expression can be used to locate the current node i.e. Google Search button.
|
1 2 3 |
XPath=//input[@name='btnK'] |

Now using the parent axes, we can identify the Google Search text box.
|
1 2 3 |
XPath=//input[@name='btnK']/parent::*/parent::*/parent::div[1]//input[@name='q'] |
Child
|
1 2 3 |
XPath=//CurrentTag[@attribute ='value']/child::tagName |
The grandchild can be located as follows.
|
1 2 3 |
XPath=//CurrentTag[@attribute ='value']/child::tagName/child::tagName |
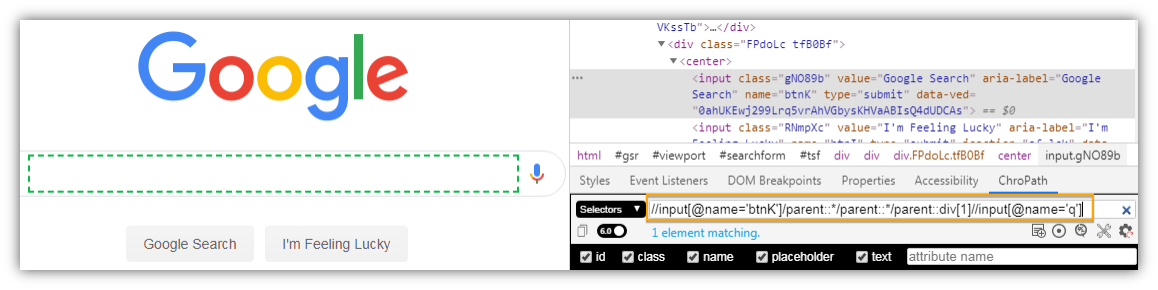
Let’s understand it again using the google search page. We will consider the particular Div tag as the current element inside which there are two buttons. Using child axes we will specifically locate the Google Search button.
The following XPath expression can be used to locate the particular Div tag.
|
1 2 3 |
XPath=//div[@class='FPdoLc tfB0Bf'] |
 Now using the child axes, we can identify the Google Search button.
Now using the child axes, we can identify the Google Search button.
|
1 2 3 |
XPath=//div[@class='FPdoLc tfB0Bf']/child::*/child::input[1] |

Ancestor
The Ancestor XPath axes are used to locate the parent and grandparent tag of the current element tag.
The syntax of locating ancestor axes is as follows.
|
1 2 3 |
XPath=//CurrentTag[@attribute ='value']/ancestor::tagName |
We will try to understand it using the Instagram login page. On this page, there is a “Forgot password?” hyperlink. First, we will locate this hyperlink and with the help of this and ancestor axes, we will further locate the Instagram title text. The “Forgot password?” link can be located by the following XPath.
|
1 2 3 |
XPath=//a[@class='_2Lks6'] |
 If we write the following XPath in the ChroPath plugin command executor field it will highlight all the ancestors of the “Forgot password?” link.
If we write the following XPath in the ChroPath plugin command executor field it will highlight all the ancestors of the “Forgot password?” link.
|
1 2 3 |
XPath=//a[@class='_2Lks6']/ancestor::* |

Now using the ancestor axes in the XPath expression we can locate the Instagram title text.
|
1 2 3 |
XPath=//a[@class='_2Lks6']/ancestor::*/h1[1] |

Note: The difference between parent and ancestor tag is that parent axes only select an immediate direct ancestor however ancestor axes select all parents and grandparents.
Descendant
The descendant XPath axes are used to identify the child and grandchild tag of the current element tag. The syntax of locating ancestor axes is as follows.
|
1 2 3 |
XPath=//CurrentTag[@attribute ='value']/descendant::tagName |
Let’s try to understand it with an example of the Instagram login page. The username, password text field, and Login button are inside a form. We will consider this as the current tag which can be located by the following XPath expression.
|
1 2 3 |
XPath=//form[@id='loginForm'] |
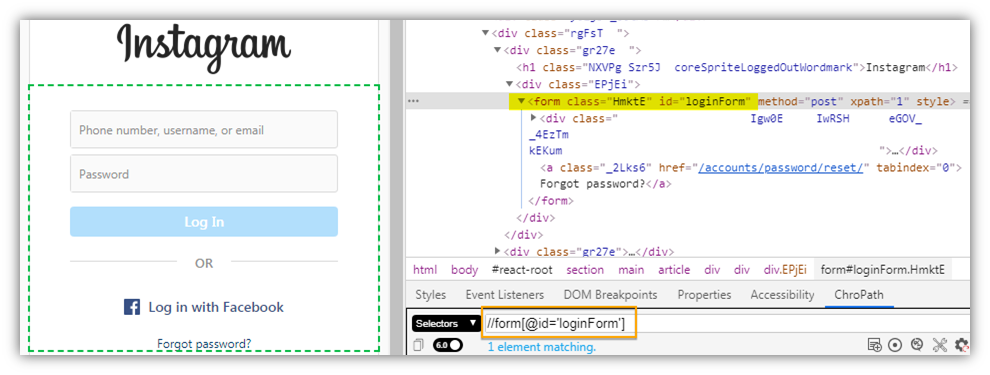 Now using descendant axes we can locate all input elements inside it and we can identify the username field using the first index. So the actual XPath expression to locate the username field will be as follows.
Now using descendant axes we can locate all input elements inside it and we can identify the username field using the first index. So the actual XPath expression to locate the username field will be as follows.
|
1 2 3 |
XPath=//form[@id='loginForm']/descendant::input[1] |

Note: The difference between Child and Descendant tag is that child axes only select an immediate direct descendant however descendant axes select all child and grandchilds.
Conclusion – Uses of XPath in Selenium Webdriver
We have seen various ways of using XPath expressions in the Selenium WebDriver.However, one should always try to identify an element by using locators like name, id as Selenium takes very little time to identify an object by using primary locators. If the web element has no unique name and id property we can go for XPath.


