A regular expression is a special string that describes a search pattern of characters. The abbreviation for regular expression is regex or regexp. The regular expression in UFT is used to represent one of the properties of the object to identify it. Regular Expression in UFT helps in identifying objects having dynamic properties.
Regular Expression Syntax
Given below is the table listing down all the regular expression metacharacter syntax.
| Symbol | Description |
| ^ | Matches the beginning of the line. |
| $ | Matches the end of the line. |
| . | Matches any single character except a newline. |
| […] | Matches any single character in brackets. |
| [^…] | Matches any single character not in brackets. |
| \A | Beginning of the entire string. |
| \z | End of the entire string. |
| \Z | End of the entire string except for allowable final line terminator. |
| re* | Matches 0 or more occurrences of the preceding expression. |
| re+ | Matches 1 or more of the previous thing. |
| re? | Matches 0 or 1 occurrence of the preceding expression. |
| re{ n} | Matches exactly n number of occurrences of the preceding expression. |
| re{ n,} | Matches n or more occurrences of the preceding expression. |
| re{ n, m} | Matches at least n and at most m occurrences of the preceding expression. |
| a| b | Matches either a or b. |
| (re) | Groups regular expressions and remembers the matched text. |
| (?: re) | Groups regular expressions without remembering the matched text. |
| (?> re) | Matches the independent pattern without backtracking. |
| \w | Matches the word characters. |
| \W | Matches the nonword characters. |
| \s | Matches the whitespace. Equivalent to [\t\n\r\f]. |
| \S | Matches the non-whitespace. |
| \d | Matches the digits. Equivalent to [0-9]. |
| \D | Matches the non-digits. |
| \A | Matches the beginning of the string. |
| \Z | Matches the end of the string. If a newline exists, it matches just before a newline. |
| \z | Matches the end of the string. |
| \G | Matches the point where the last match finished. |
| \n | Back-reference to capture group number “n”. |
| \b | Matches the word boundaries when outside the brackets. Matches the backspace (0x08) when inside the brackets. |
| \B | Matches the nonword boundaries. |
| \n, \t, etc. | Matches newlines, carriage returns, tabs, etc. |
How to Use Regular Expression in UFT/QTP
Regular Expression is used in Object Identification in object repository as well as descriptive programming. Consider a website that displays month and date.

As the text property is all properties except object class are dynamic and nature and change every other day and month, it would become a challenging task if you have to check whether this web element exists and correctly displays month and date in the required format. So how to figure out such scenarios. This is where we can use a regular expression.
If the property of the object is spied using object spy, the following properties are displayed.
“Class Name:=WebElement”,
“innerhtml:=Mar 23, 2018”
“innertext:=Mar 23, 2018”,
“outerhtml:=Mar 23, 2018”
“outertext:=Mar 23, 2018”,
There are two ways to use regular expression in UFT/QTP.
- Using regular expression with Object Repository
- Using regular expression in Descriptive Programming
To know more about Descriptive Programming(DP) please click here to refer to the detailed post on DP.
Using regular expression with Object Repository
First, prepare the regular expression for the required object property. Here we have to prepare the patter to match Mar 23, 2018. We have to take care of the following things while creating the regular expression for the date field.
- It starts with a capital letter of the month. The pattern would be [A-Z].Any capital letter between A to Z
- The month is represented by three characters. The pattern would be [a-z]{2}.Any two letters between a to z.For the first character, we have already created the patter.
- After the month’s name, there is a space character. The pattern would be \s. Any white space.
- The date part is represented by 2 digits followed by a comma. The first digit would be between 0 to 3. So that patter would be [0-3]. The second digit would be [0-9]. The comma can be written as it is.
- After the comma, there is a space character and then 4 digit year. The pattern would be like \s20\d\d. A \d means any digits between 0 to 9.
- Hence the complete regular expression would be [A-Z][a-z]{2}\s[0-3][0-9],\s20\d\d.
To write the regular expression, go to Tools>Regular Expression Evaluator. It will open a utility to write and evaluate a regular expression.

Write the required text that needs to be evaluated against the regular expression in the Sample Text editor. Now write the expected regular expression pattern in the Regular Expression field. To evaluate the regular expression click on the Highlight button. If it highlights the whole pattern, it means the regular expression is correct. If it highlights the partial text, you will have to update the regular expression to get it to match with the complete sample text.

Now open the object repository and select the required object from the Test Objects tree and select the property of the test object that needs to be parametrized with a regular expression and click the <#> icon.
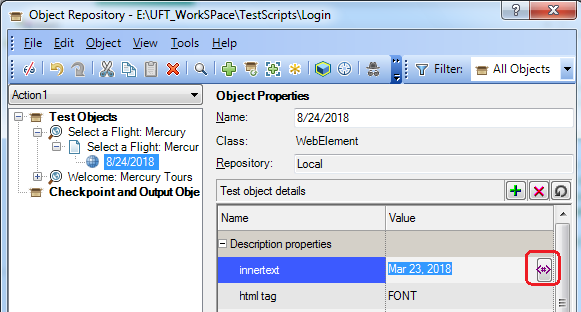
It will open a popup window to configure regular expression.

Select the regular expression checkbox to enable regular expression. You might get an alert box to add a backslash(\) before each special character. Click on either the Yes or No button depending on the regular expression pattern. An additional backslash nullifies a special character in the regular expression pattern.

After that press the OK button. Now the “innertext” property of the object has been successfully parametrized with a regular expression. To check whether UFT is able to identify the object press the cube button provided the application is in the open state. UFT will highlight the object in the application.

Using regular expression in Descriptive Programming
|
1 |
Browser("A").Page("B").WebElement("innertext:=[A-Z][a-z]{2}\s[0-3][0-9],\s20\d\d").Exist |
If you are creating object description using object collection and want if you want any specific property say “name” not to be recognized as the regular expression then you need to set the “regularexpression” property as FALSE as shown below.
|
1 2 3 |
ObjDesc("html tag").value = "INPUT" ObjDesc("name").value = "txt.*" ObjDesc("name").regularexpression = FALSE |
Recommended Posts
- File System Object UFT | VBA
- All You Need to Know About Object Identification in UFT
- DataTable in UFT One | Example of Datatable Methods
- Micro Focus UFT Tutorial – An Overview of UFT
- Descriptive Programming in UFT with Examples
- How to Use Environment Variables in UFT
- How to Use WaitProperty | Dynamic Wait in UFT
- VBScript Loops: Do Loop, For Loop, For Each, and While Loop
- VBScript MySQL Database Connection in UFT


